Casey Muratori is wrong about clean code (but he's also right)
First things first...
I'd like to get one thing out of the way. Despite the click-bait headline, I think that Casey is right about a lot of things. It seems to me that programming for performance is becoming a lost art and I think Casey is doing great work as an advocate for writing code designed to perform well. So I agree with many of the principles he talks about and feel that he is shining a light on how non-performant most of the code we see today is. I hope he continues to do this. As someone who self-identifies as a developer who loves to optimize code and squeeze every last bit of speed out of it, I find myself nodding along with many of his points. Everyone should read his blog post at https://www.computerenhance.com/p/clean-code-horrible-performance too see a good demonstration of how he uses his principles to squeeze a ton of performance out of one of the first examples of OOP that beginners get shown in school.
I wouldn't be writing this unless there was a "but", so here we go :-). Spoiler alert, in the end, it's complicated and there are no hard and fast rules. Always profile your code to know what is fast and what isn't!
UPDATE: A reader on reddit pointed that the shapes were in a predictable pattern. So I've added one last section to the end to test again with some randomization. The results continued to surprise!
Where I disagree with Casey is that while I think he definitely knows how to write code in his personal style very well, I find his critiques of things like "clean code" and "modern C++" to be unbalanced. I'm putting those words in quotes because I don't think that we necessarily have agreement on what those things are. So let's talk about it. I promise that by the end of this there will be benchmarks and hard data to talk about, but first I'd like to get on the same page about what these things mean to me.
NOTE: It can be difficult sometimes to write about what other people are thinking, and it is never my intention to misrepresent anyone's position. So if any part of this feels like that, it is not intentional and I am happy to correct it accordingly.
What is "clean code"?
The first thought that entered my head after reading Casey's blog was "Both Casey's code and the example code both look pretty clean to me!" I would even go so far as to argue that Casey's code didn't even break most of the clean code principles he outlined. So why are we in disagreement about that? Definitions of course. Here is Casey's list of "clean code" principles that he is talking about.
Prefer polymorphism to "if/else" and "switch"
I simply don't agree "clean code" equates to preferring polymorphism. Yes, many people advocate for runtime polymorphism as opposed to conditional logic, including Robert C. Martin. But to me, virtual functions are a tool, and every tool has its time and place. I don't think that one is cleaner or even more maintainable than the other in absolute terms. Instead, I believe that virtual functions are a trade-off of runtime performance in order to achieve certain types of flexibility in the code. Perhaps something like the ability to load plugins at runtime where you really don't know all the needs of the code statically beyond its interface. But I generally wouldn't ever advocate for using them in a tight loop, because yes, they are slower than most alternative solutions. My main argument is that nearly all of the slowness that Casey demonstrates is due to virtual function dispatch, and not the other things he mentions. I will provide benchmarks to demonstrate this later...
Code should not know about the internals of objects it’s working with
I think this rule is too broad to be useful. I would reword it as "Code should not inappropriately know about the internals of objects it’s working with". It may not seem like a lot, but I feel that that one word makes a huge difference. What I mean is that C++ has the friend keyword for a reason. If we're choosing to design things in terms of objects, and several distinct classes or blocks of code need to work together for a common goal, then it may very well make sense to be granted access to each other's internals. This can actually improve your design significantly by granting access to the classes and functions that need it while preventing code that doesn't need it from causing a problem.
I can say that I agree with Casey that if you're writing code like this:
class T {
public:
int getValue() const { return value_; }
void setValue(int v) { value_ = v; }
private:
int value_;
}
Then you are literally wasting your time writing useless code and making the compiler's job harder. Just make the member public; you're letting everyone read and write the value anyway. As with all things, private members and accessor functions have a time and place. They are not something to be used always or by default.
Functions should be small
I think this one is simple. Casey's functions are small. My personal rule of thumb is that a function should generally fit on one screen. Your milage may vary, but if it's less than 40 lines, it's "small enough" for me to call it clean. I don't think small has to mean "trivial", I think it should mean "I can keep the logic for it in my head and see it all at a glance".
Functions should do one thing
Again, I'd argue that Casey's function are doing one thing. In his post, Casey introduces a function called CornerArea as a demonstration that adding more complexity to the problem amplifies the slowdown effect. And presents this function as one which computes corner-weighted areas arguing that maybe clean code advocates would say to put this code into yet another function, adding even more abstraction and indirection to the problem, thus it is doing multiple things. But I'd still argue that this new function is still doing one thing, it's calculating the "corner-weighted areas". That's it.
To me, saying a function should do one thing means that a function should either have a side effect, or it should calculate something, it probably shouldn't do both. My rule of thumb is that if I every feel tempted to write a function with words like "and" or "or" in the name, I'm probably making a mistake. So I won't every write a function like float setTemperatureAndCalculateHumidity(). To me, that leads to hard to comprehend code.
"DRY" - Don’t Repeat Yourself
We agree. Nothing more to say. Hopefully at this point we're on the same page at least about what these words mean to me, and it's understandable why I might feel that Casey shouldn't really arguing against "clean code", since his own code easily meets most of what I consider to be "clean".
Let's talk performance
At the beginning of this, I stated that I think that basically all of the performance issues Casey demonstrated had to do with virtual functions and not "clean code". Time to put my money where my mouth is and prove it! First, let's replicate Casey's results. I'm going to use https://quick-bench.com/ since it lets users play with the code and see the results on the fly!
Casey didn't provide his test harness, but I think we can easily come up with something fair. For the v-table based version I create the shapes like this:
// not part of the benchmark
srand(0); // predictable seed
shape_base *shapes[Count];
for (int i = 0; i < Count; i++) {
switch (i & 3) {
case 0:
shapes[i] = new square(rand());
break;
case 1:
shapes[i] = new rectangle(rand(), rand());
break;
case 2:
shapes[i] = new triangle(rand(), rand());
break;
case 3:
shapes[i] = new circle(rand());
break;
}
}
and for the switch based case I create shapes like this:
// not part of the benchmark
srand(0); // predictable seed
shape_union shapes[Count];
for (int i = 0; i < Count; i++) {
switch (i & 3) {
case 0:
shapes[i] = {Shape_Square, static_cast<f32>(rand())};
break;
case 1:
shapes[i] = {Shape_Rectangle, static_cast<f32>(rand()), static_cast<f32>(rand())};
break;
case 2:
shapes[i] = {Shape_Triangle, static_cast<f32>(rand()), static_cast<f32>(rand())};
break;
case 3:
shapes[i] = {Shape_Circle, static_cast<f32>(rand()), static_cast<f32>(rand())};
break;
}
}
With constexpr int Count = 128;. Increasing this number didn't seem to effect the results in any meaningful way. But readers are free to try other values so long as they are a multiple of 4.
I don't think that the actual shape dimensions really matter for this experiment so I just initialize them to random values.
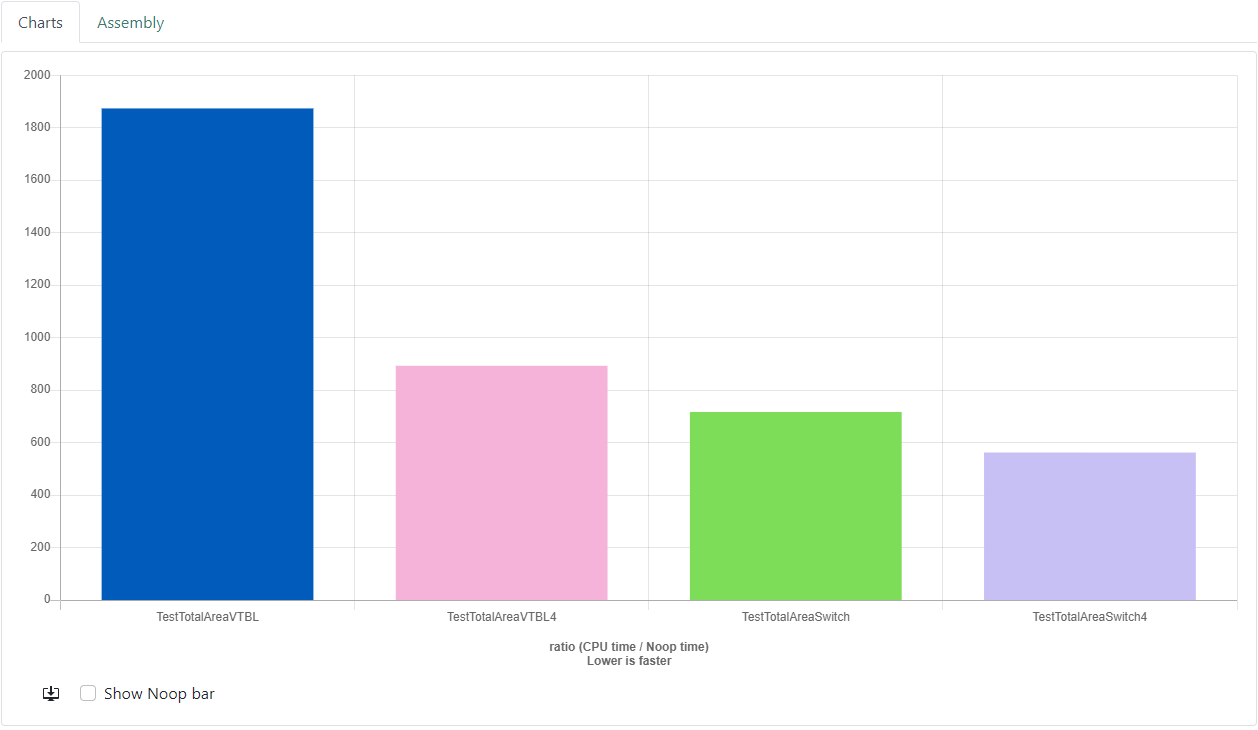
Neither of these blocks of code are included in the actual benchmark. As you can see the v-table version does the typical thing and allocates on the heap (destroying cache locality) and Casey's version just packs them into a contiguous array. I could argue that using an arena allocator to make the shapes at least near each other in memory would change the results.. but let's keep it simple and in line with how I expect Casey implemented his version. The results are pretty much as expected and generally match Casey's results to a reasonable degree. The VTBL version is notably slower than the switch version. Interestingly, I saw a larger gain from the VTBL4 version where the loop is unrolled into groups of 4.
Here's the results:
-
GCC-12.2 https://quick-bench.com/q/v6Aj5WEVSxS4Ns9Qg9cSGutvf0
-
Clang-15.0: https://quick-bench.com/q/od7F_SMFkOSzMxNlhMjmFcfvMjk
Things are looking pretty bleak for VTBL!
Let's introduce some modern C++
My understanding is that Casey doesn't like modern C++. I think that not only does he not like it, but he also tends to avoid knowing about what's been added in recent years. I don't mean this as an attack on Casey. I just think that when he's thinking about "modern C++", he isn't thinking about the same features and techniques that people who like C++ are. I want to make it clear, that's also OK by me. Casey is a very effective programmer who gets things done, he is under no obligation to have even heard about features introduced in something like C++17, let alone like them or use them. Me though... I like C++, a lot. Not because it's perfect, far from it. I like C++ because its abstractions and features make sense to me and I enjoy the level of control it offers. So how would I write this example while still keeping the shapes as distinct types? std::variant. For the uninitiated, std::variant is a discriminated union type in C++, which allows you to have both distinct types for our things and to pack them in tightly together in memory. Finally, we have std::visit function which lets you execute code on the active object in the variant clearly and concisely. Combine with lambdas as we get some pretty sleek code. Let's try it!
Firstly, shape_base can go away, we don't need it for std::variant to work. Next, let's get rid of those virtual keywords since that is (in my opinion) the real culprit here. While we're massaging the code to make it modern, let's make the Area functions const. I don't think it'll affect performance, but it's what I'd write.
Next, we'll introduce the variant type that can hold all of these things. So now our classes look like this. The code ended up not being that different from the original polymorphism-based version.
class square {
public:
square(f32 SideInit)
: Side(SideInit) {}
f32 Area() const { return Side * Side; }
private:
f32 Side;
};
class rectangle {
public:
rectangle(f32 WidthInit, f32 HeightInit)
: Width(WidthInit), Height(HeightInit) {}
f32 Area() const { return Width * Height; }
private:
f32 Width, Height;
};
class triangle {
public:
triangle(f32 BaseInit, f32 HeightInit)
: Base(BaseInit), Height(HeightInit) {}
f32 Area() const { return 0.5f * Base * Height; }
private:
f32 Base, Height;
};
class circle {
public:
circle(f32 RadiusInit)
: Radius(RadiusInit) {}
f32 Area() const { return Pi32 * Radius * Radius; }
private:
f32 Radius;
};
using any_shape = std::variant<square, rectangle, triangle, circle>;
OK, now we need to update our test functions to use std::visit. Definitely a departure from classical C++, but nothing too bad once you've seen it before:
f32 TotalAreaVariant(u32 ShapeCount, any_shape *Shapes) {
f32 Accum = 0.0f;
for (u32 ShapeIndex = 0; ShapeIndex < ShapeCount; ++ShapeIndex) {
Accum += std::visit([](auto &&shape) { return shape.Area(); }, Shapes[ShapeIndex]);
}
return Accum;
}
f32 TotalAreaVariant4(u32 ShapeCount, any_shape *Shapes) {
f32 Accum0 = 0.0f;
f32 Accum1 = 0.0f;
f32 Accum2 = 0.0f;
f32 Accum3 = 0.0f;
u32 Count = ShapeCount / 4;
while (Count--) {
Accum0 += std::visit([](auto &&shape) { return shape.Area(); }, Shapes[0]);
Accum1 += std::visit([](auto &&shape) { return shape.Area(); }, Shapes[1]);
Accum2 += std::visit([](auto &&shape) { return shape.Area(); }, Shapes[2]);
Accum3 += std::visit([](auto &&shape) { return shape.Area(); }, Shapes[3]);
Shapes += 4;
}
f32 Result = (Accum0 + Accum1 + Accum2 + Accum3);
return Result;
}
Finally, we update the test harness. I'm going to put the shapes in a std::vector since that's the easiest way to initialize the array. In my opinion this should not effect the results since a std::vector is a simple wrapper around an array and its creation is not part of the benchmark at all. If anyone objects, just let me know and I'll use a different way to initialize the array. But if anything, it can only work against me.
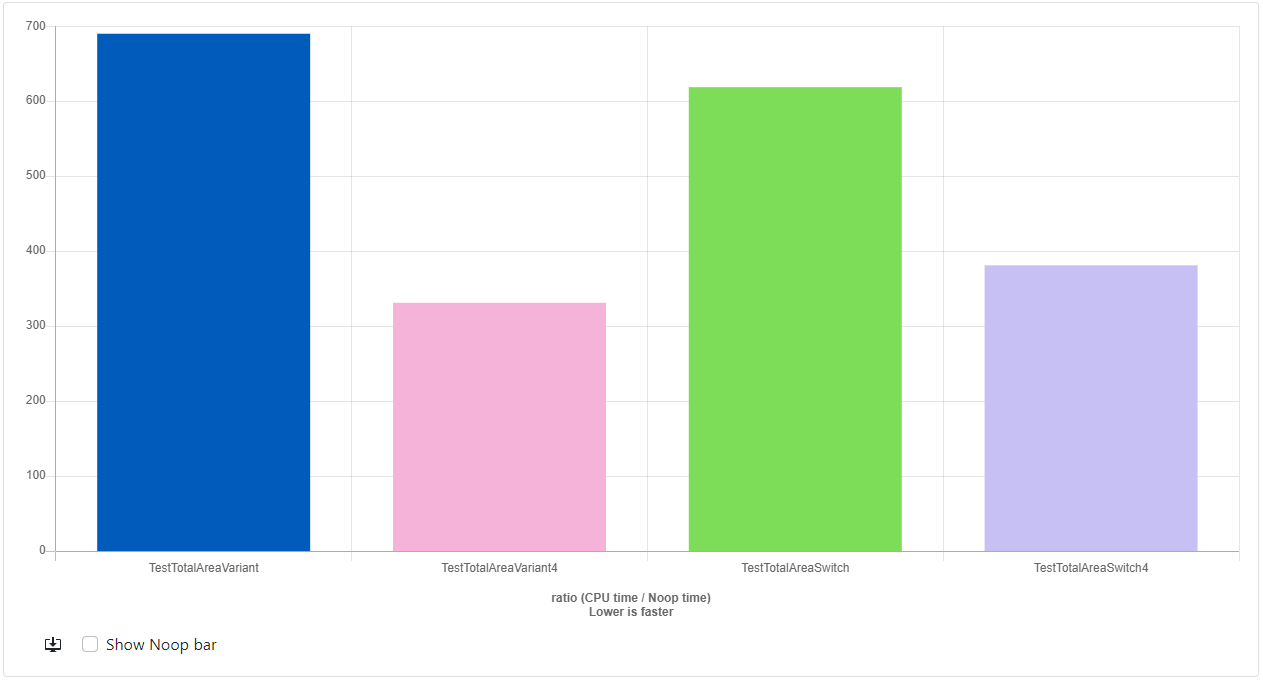
So how does it perform?
- GCC-12.2: https://quick-bench.com/q/qLr920K5kHMsXKCA5OdJ6iNIR6o
- Clang-15.0: https://quick-bench.com/q/vhAwcWW24PDmJwS6e_t67C1zsBM
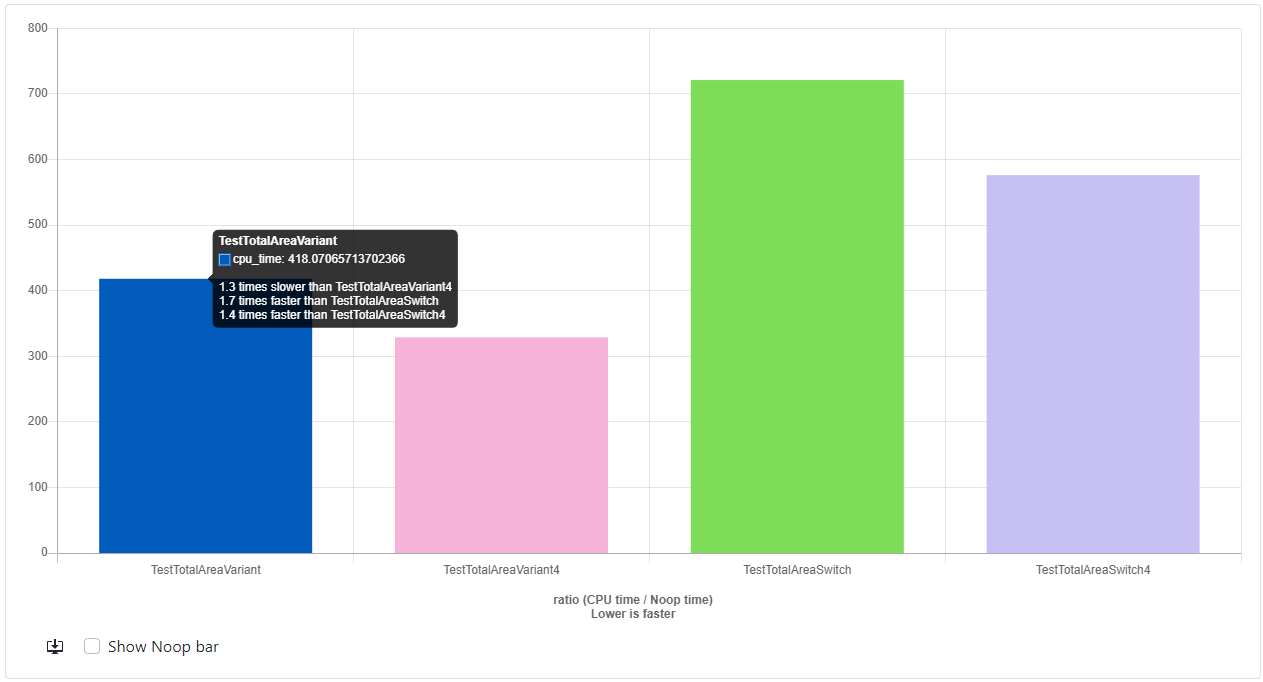
Now things are getting interesting!
The first takeaway is that Clang and GCC are doing wildly different jobs in optimizing my code. With GCC, The variant version is slightly slower than the switch version but by a relatively small margin and the unrolled version ends up beating everything, even the unrolled switch. The Clang story is a little more straightforward as it just has variant beating switch statements across the board with the TotalAreaVariant4 function 1.8x faster than the TestTotalAreaSwitch4 version.
What's happening here? Why is variant faster? Here's my theory without looking at the disassembly:
std::visit ends up basically generating a cascading if chain at compile-time, and my guess is that for such a small collection of types, the compiler is able to better optimize that than a switch. One thing that isn't always common knowledge about C++ is that enums can take on integer values outside those listed in the enumeration. So when the compiler is generating a switch statement, it often has to account for that possibility. Perhaps using a compiler directive to say that the other cases can't happen would get some small amount of performance back, but it's hard to say because at this point I'm speculating.
So there are a couple of things to think about.
- Different compilers optimize things differently and have different strengths and weaknesses. If you have the luxury of targeting a specific toolchain, then, of course, use the constructs that the compiler is best at optimizing.
- Profile, profile, profile! You never know how things perform until you actually profile it. I didn't expect
variantto ever exceed theswitchversion. I expected it to at best break even, perhaps be slightly behind due to abstraction costs.
What about the "CornerArea" versions?
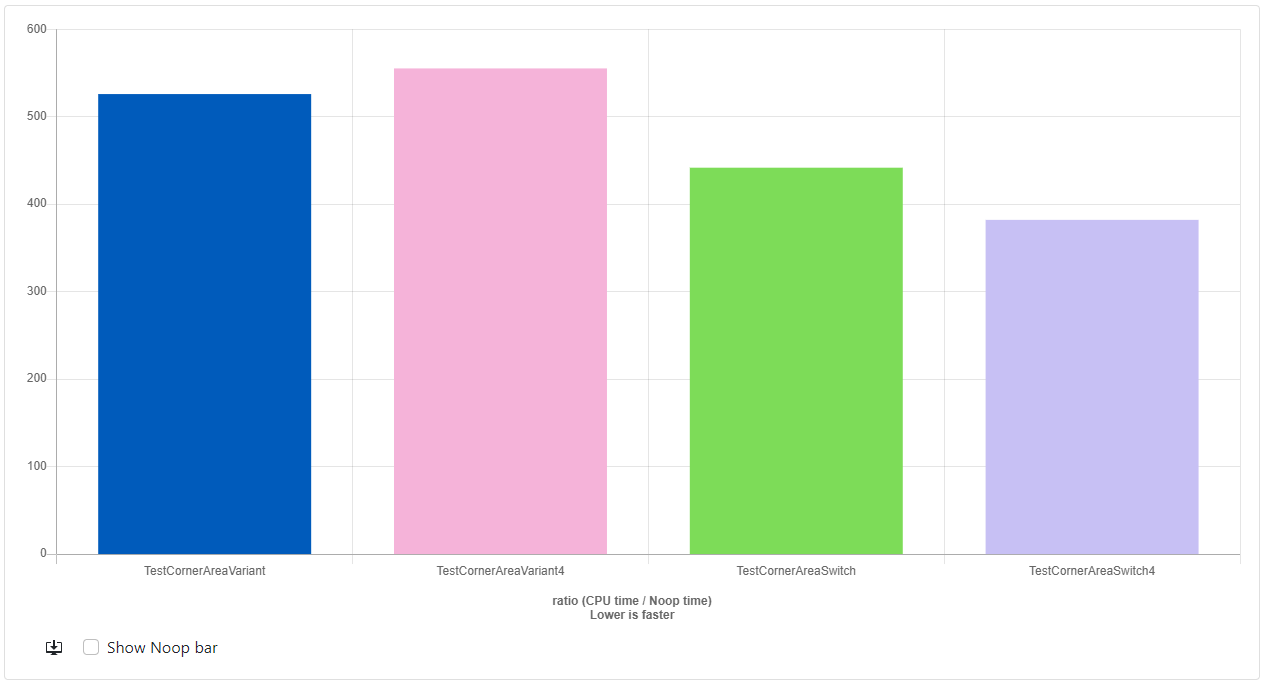
Don't worry I didn't forget them. After updating the code using a similar methodology I got these results:
- GCC-12.2: https://quick-bench.com/q/crYrRIDAnyAju5INgIGSWtT3KHk
- Clang-15.0: https://quick-bench.com/q/Awd8j1hx9dmgW6j1LHrTu6Ymh5E
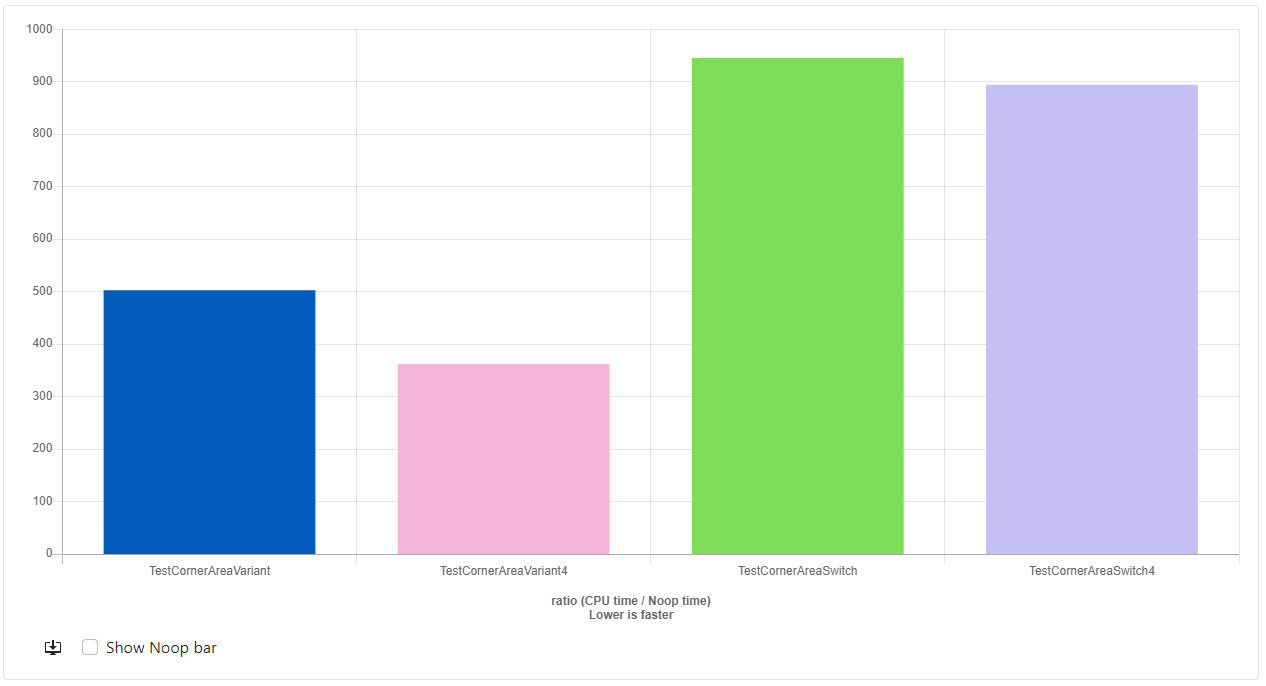
Again the results are full of surprises. With GCC, the variant version is indeed slower than the switch version. And the unrolled variant version is actually slower than the regular variant version, maybe this has something to do with the instruction cache size? I'm not sure. But with Clang... the variant version simply blows the switch version out of the water at a speed of 2.5x the CornerAreaSwitch4 version! That was very much not expected at all.
OK, so the problem is virtual functions and not "clean code", what about the table solution at the end?
I haven't yet benchmarked my alternatives to Casey's solution for two reasons:
- His table solution is pretty optimal (short of using SIMD). At a speed of 3 cycles per shape (holy cow!), he's bordering on having each shape only needing a small handful of CPU instructions to process. That's pretty damned cool and really fast. If he's on a 4GHz machine, that's basically less than a nanosecond per shape. very impressive
- The table-based solution isn't really an apples-to-apples comparison anymore.
Let me explain that second point by looking at his code:
f32 const CTable[Shape_Count] = {1.0f / (1.0f + 4.0f), 1.0f / (1.0f + 4.0f), 0.5f / (1.0f + 3.0f), Pi32};
f32 GetCornerAreaUnion(shape_union Shape)
{
f32 Result = CTable[Shape.Type]*Shape.Width*Shape.Height;
return Result;
}
There's an important detail here that is very easy to overlook. I don't think many people would catch it, I certainly didn't at first. It wasn't until I thought about it for a long time that I noticed something...
Casey has pushed about half of the calculation to compile time. Those expressions like 1.0f / (1.0f + 4.0f) are resulting in compile-time constants. This is because one of the most basic compiler optimizations out there is constant folding. That means that if you write any mathematical expression that consists of all constant values. The compiler is going to calculate it for it at compile-time. Those expensive float divisions? They simply don't happen at runtime.
So while I agree that Casey's last example is optimal, it also is no longer doing the same work since much of the work is being now pre-calculated. If you happen to know a lot of the data at compile-time, then I agree, you should push as much of the calculation to compile-time as possible. And often that means having lookup tables as Casey has done. It's a completely valid approach... but it's also solving a problem with different specifics. One thing that is universally true about optimization, is that the more assumptions you can make about the data, the more optimizations you can use. This last example is introducing a new assumption: that we know these things at compile-time. Which may be fair! But it's also a different discussion in my opinion.
Being a "modern C++ nerd", maybe I should follow this up with a comparison between that and constexpr functions.
Conclusions
I hope that this can contribute to a positive conversion about modern/clean code and how it effects performance. I'd like to reiterate that I think that Casey is putting great content out there which I hope will inspire more developers to think about performance. I honestly did my best to make the comparisons fair, and if I've overlooked something, I'm happy to correct it and update the article.
I do think that because Casey doesn't care for modern C++ that he simply wouldn't ever reach for those tools. He doesn't want them in his toolbox, and that's fine by me; different strokes for different folks. All of that being said, I do think that I've shown that at least in this example, we can have our cake and eat it too. We can have our abstractions, we can have our classes (if we really want to do that, C++ doesn't mean we have to use OOP!), and we can still get great performance if we try.
(Update: 2023/04/13): Branch Prediction
OK, So I did miss at least one thing. Branch Prediction. A reader pointed out to me that not only were the shapes in a predictable pattern, but the pattern had a cycle of size 4. Which would make the loop unrolling particularly effective since it was unrolled by a factor of 4. Making the predictions align perfectly. I think this is a fantastic insight and needs to be included in the discussion. Again, being able to make assumptions about your data means you can make it fast. So keep in mind that if you're able to cheaply reorder your data so it becomes more predictable, you may be able to get some non-trivial wins.
Let's randomize it!
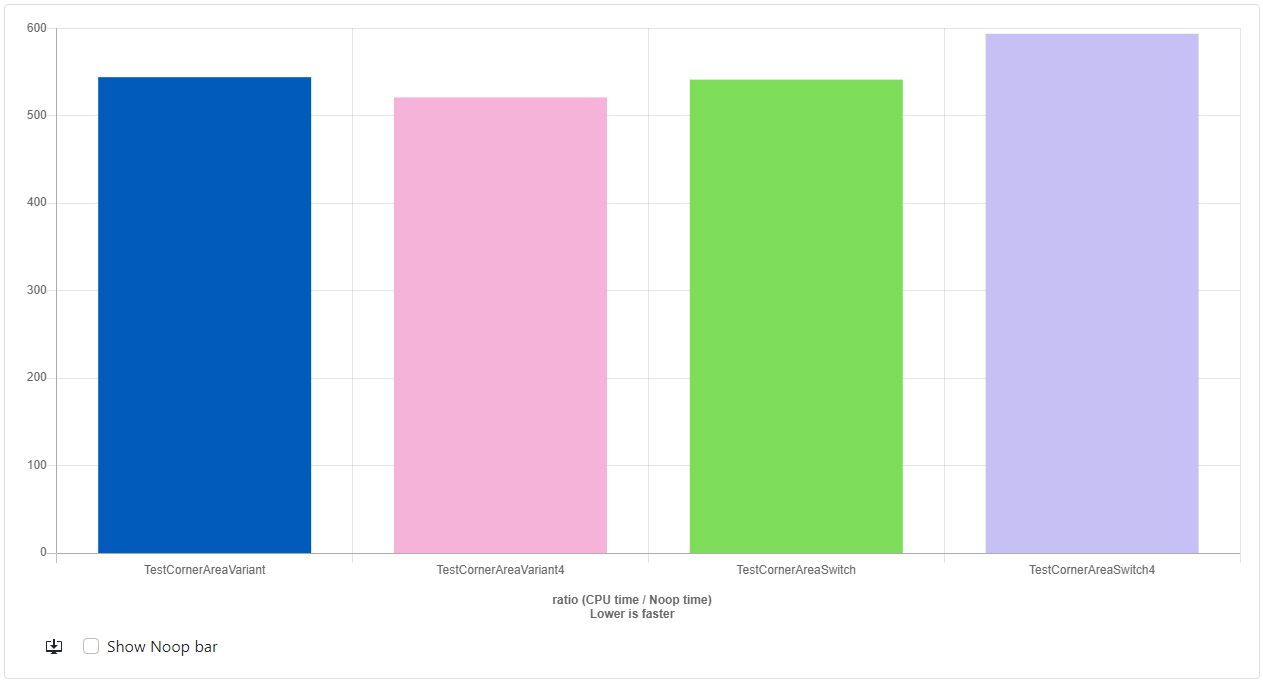
The change I made for this is pretty straight forward. I made it so the switch statement that creates the shapes is now based on based on rand() & 3 instead of i & 3. I am aware that rand is not a great source of randomness in the general case, but I think this is unpredictable enough to give the CPUs branch predictor a hard time. I also only re-tested with the "CornerArea" versions since that was the most complex version of the example code. So how'd we do? The results were very surprising:
- GCC-12.2: https://quick-bench.com/q/AkkSW5279D2FxwKoieewE1GBAYg
- Clang-15.0: https://quick-bench.com/q/Awd8j1hx9dmgW6j1LHrTu6Ymh5E
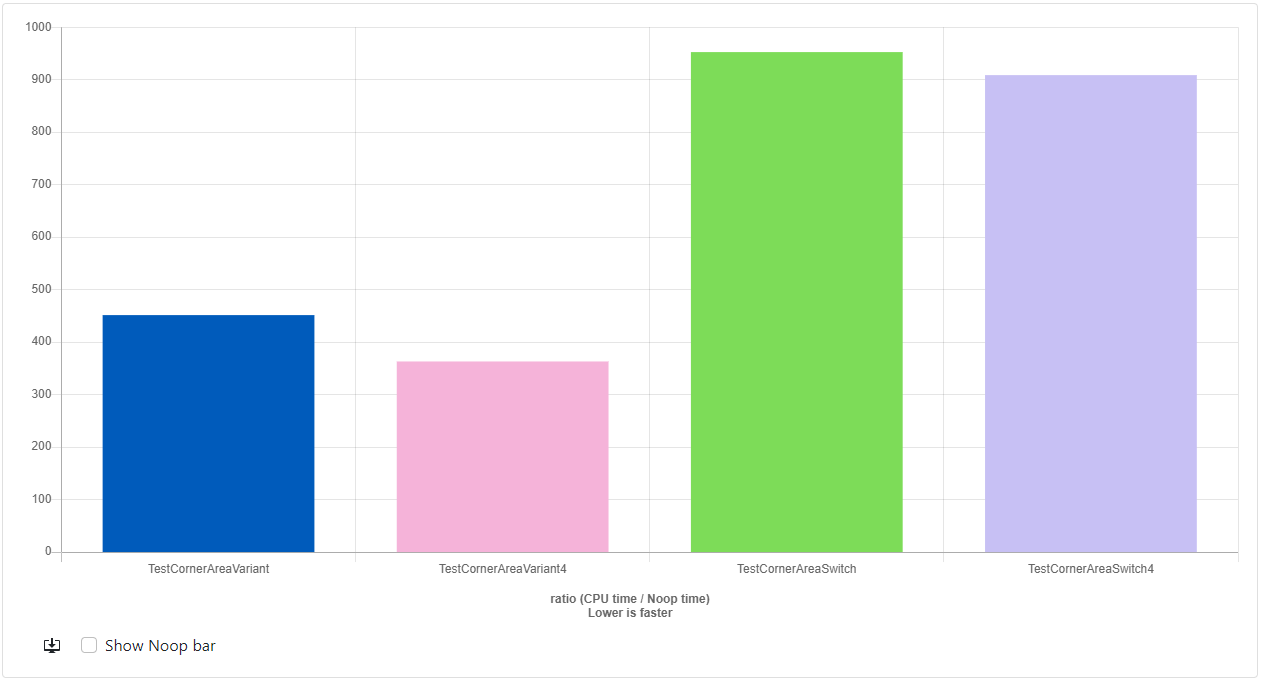
For GCC, it seems to have basically leveled the playing field. All the results seem to be approximately the same speed regardless of loop unrolling. This is actually what I'd have expected. But Clang continues to impress. The variant version is still out-performing the switch version by a wide margin. I'm going to have to investigate how this is possible, but if I were to guess, I think that maybe Clang is being very aggressive about inlining code.